
Чи зможе людина навчити штучний інтелект вигулювати собак, чим ШІ схожа на дитину, чому машини швидко еволюціонують у віртуальному, а не в реальному світі, і як у цьому допомагає машинне навчання?
Розповідає лауреат наукової премії від Яндекса Олексій Шпільман.
Навчальний гайд для машин і робота над помилками
ШІ пророкує затори на дорогах, підбирає музику для плейлистів, виправляє помилки в повідомленнях, прибирає шум під час відеодзвінків - і це лише мала частина того, де він задіяний. Мільйони людей щодня стикаються з роботою штучного інтелекту, але часто навіть не здогадуються про це.
Щоб ШІ допомагав у вирішенні практичних завдань, його спочатку потрібно навчити. Проведемо аналогію: якщо людина прийшла в шаховий клуб і хоче навчитися грати, то викладач може пояснити їй, як діють фігури в певних позиціях, відпрацювати з ним комбінації ходів і так далі. А може просто дати дошку і фігурки для гри, розповісти основні правила, порекомендувати кілька підручників і сказати: далі розбирайся сам.
Перший варіант - машинне навчання з учителем (Supervised learning) - метод, при якому дослідник готує для ШІ путівник з правильними і неправильними діями. На його основі машина освоює алгоритм, який застосовує для вирішення аналогічних завдань. Як і людина, штучний інтелект отримує фідбек від вчителя, аналізує помилки і вдосконалює свою роботу.
У реальному житті цей метод використовується для передбачень погоди, виручки компаній, цін на нерухомість. Банки застосовують навчання з учителем при прийнятті рішення про видачу кредитів: ШІ аналізує клієнта за безліччю ознак, таких як вік, зарплата, стаж, кредитна історія, наявність власності, і визначає, чи здатний він повернути запитувану суму. Інший приклад сервісів, де застосовується ця технологія - голосові помічники. Створюючи Алісу, розробники Яндекса завантажили в комп'ютер безліч текстів і аудіозаписів, щоб нейромережа «навчилася» вести бесіди.
Контроль вчителя завжди був важливою умовою освітнього процесу. Але зараз звичні механіки переглядаються: частіше цінується, якщо дитині дають право на помилку і самостійний пошук. Для цього учня поміщають у симуляцію, де він відразу зможе на реальних ситуаціях відточувати різноманітні навички.
У машинному навчанні такий варіант теж можливий - до нього відноситься навчання з підкріпленням (Reinforcement learning). У цьому випадку у комп'ютера або, як кажуть вчені, у «агента», немає навчальних алгоритмів з чіткими діями. Штучний інтелект робить дію, а потім дивиться, як змінилося навколишнє середовище і його положення в ній. Якщо крок був успішним і наблизив ШІ до виконання мети, то він отримує нагороду - це стимулює його продовжувати рух в обраному напрямку. У зворотній ситуації штучний інтелект втрачає нагородні окуляри і відступає на кілька кроків назад, щоб внести зміни в ланцюжок своїх дій. Поступово освоюючись у незнайомому середовищі, машина розуміє, що від неї вимагається і якими способами краще досягти поставленого завдання.
Беремо приклад з ШІ: вчимося доводити справу до кінця і не втрачати терпіння
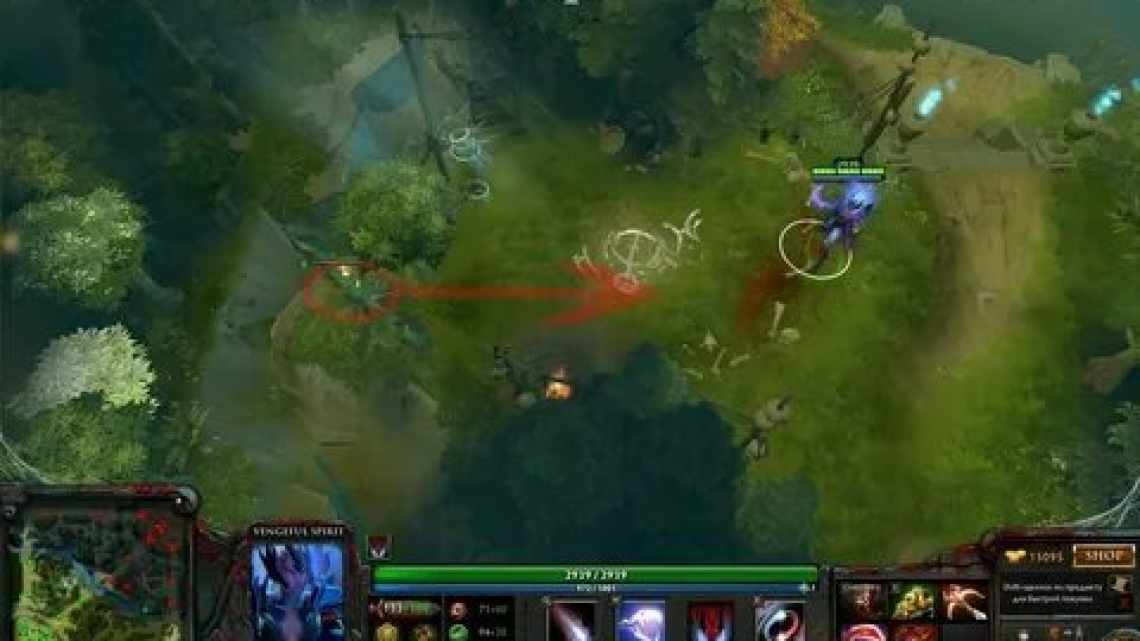
Уявімо, що ми хочемо навчити машину вигулювати собаку. Це складне завдання, яке можна розбити на етапи: робот повинен покликати вихованця до дверей, одягнути його, закріпити повідок, вийти на вулицю, стежити, щоб пес не виривався і не кидався на людей, потім повернутися додому, роздягнути, помити лапи. У рамках навчання з підкріпленням завдання машини - самостійно розкласти запит на окремі дії та знайти оптимальні шляхи їх виконання. Спочатку система може спробувати вивести собаку без повідця. Наступного разу робот одягне шлейку, але забуде утеплити собаку в мороз. Такі спроби ШІ може здійснювати незліченну кількість разів, поки не знайде оптимальний спосіб - в цьому плані він набагато більш старанний учень, ніж людина.
Освоєння складних навичок у машини поки відбувається повільніше, ніж у людини. Так, якщо порахувати час, який знадобився ШІ, щоб навчитися грати в DOTA, вийде 45 000 років. Але оскільки процес відбувається у віртуальному оточенні, то його можна прискорити і розпараллелити і тисячі років стиснути до одного року. Наприклад, боти OpenAI через десять місяців навчання посіли перше місце в турнірі The International з Dota 2, обігравши чемпіонів світу. Також компанії вдалося створити робота (а точніше роборуку), яка змогла зібрати кубик Рубіка. Для цього ШІ провів у віртуальному середовищі 10 000 симуляційних років, постійно тренуючись.
В іграх комп'ютер легко обходить найталановитіших людей, але для прикладного застосування цього недостатньо. Реальний світ набагато складніший за віртуальний: в ньому відбувається набагато більше подій, які складно спрогнозувати. Вчені працюють над тим, щоб наблизити впровадження алгоритмів RL, але це довгий і дорогий процес. Взагалі в науці корисність для суспільства не завжди формується відразу: для відкриттів часто потрібно підготувати наукову базу. Таким фундаментальним дослідженням важлива інфраструктурна підтримка.
На щастя, ринок це розуміє і допомагає вченим: наприклад, я і мої студенти брали участь у конкурсі на здобуття премії імені Іллі Сегаловича в галузі комп'ютерних наук від Яндекса. Гранти, доступ до спеціалізованих ресурсів для машинного навчання та увага ек "